

一、客户挑战:为下一代AI模型寻找“超级引擎”
我们的客户,作为AI领域的先行者,其研发团队正致力于探索参数量高达千亿甚至万亿级别的大模型。在此过程中,他们原有的计算设施面临着三大核心挑战:
1. 算力瓶颈:现有GPU算力不足以支撑如此大规模模型的训练,研发周期被无限拉长;
2. 通信效率低下:在大规模分布式训练中,节点间的网络延迟成为制约整体性能的木桶短板;
3. I/O瓶颈:海量的训练数据集和TB级的模型检查点,对存储系统的读写性能提出了前所未有的要求。
为了支持其下一代AI模型的研发,客户迫切需要一套全新的、无瓶颈的、面向未来的高性能计算平台。
二、我们的解决方案:精益求精的架构设计
针对客户的核心需求和项目规模,我们设计并集成了一套集性能、效率与经济性于一体的AI算力集群。我们的架构设计亮点如下:
· 计算核心 - 8 x NVIDIA H系列 GPU服务器(共64颗 H系列GPU):
我们为客户选择了专为生成式AI打造的旗舰级H系列GPU。其141GB HBM3e高速内存,为客户处理超大规模模型提供了无与伦比的单点计算能力。
· 计算网络 - 4OOG NDR InfiniBand网络:
为了彻底消除GPU间的通信瓶颈,我们部署了业界顶级的4OOG NDR InfiniBand网络。这套专用的“计算高速公路”,通过其超低延迟和NVIDIA SHARP™技术,确保了客户在进行大规模并行训练时,能够获得近乎线性的性能扩展。
· 统一数据网络 - 200G融合以太网架构:
考虑到当前集群规模和客户对运维简便性的要求,我们为客户推荐并实施了更为灵活和经济的融合网络设计:将数台高性能存储服务器与GPU计算节点直接接入到同一个2OOG以太网交换网络中,统一承载存储和业务流量。这一设计不仅简化了网络拓扑、降低了客户的初始投入和后期运维难度,200G的巨大带宽也完全满足了两种关键流量的性能需求。
· 海量存储底座 - 1PB高性能存储系统:
我们为客户配置了1PB容量的高性能并行文件系统,通过统一的200G以太网,为所有计算节点提供持续、稳定的高吞吐数据流,确保GPU集群的强大算力得到100%的发挥。
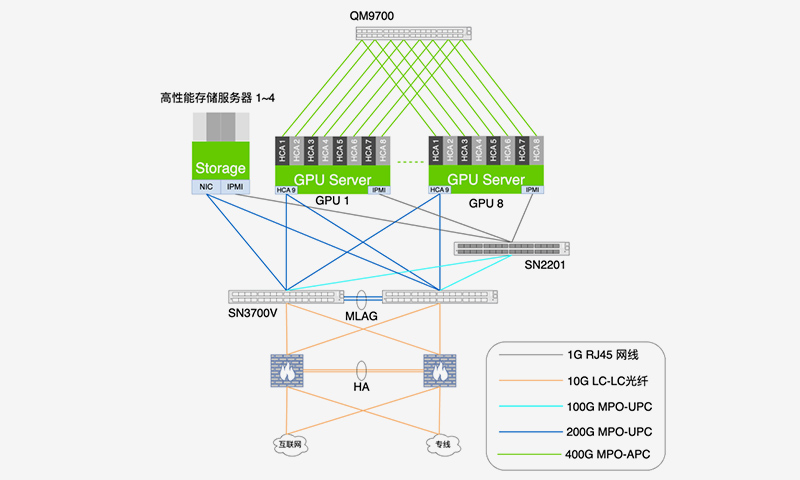 组网拓扑图
组网拓扑图
三、项目成果:为客户带来的卓越价值
集群交付后,客户立即将其投入到核心AI研发项目中,并向我们反馈了卓越的性能表现和业务成效:
· 研发效率指数级提升:在客户的一个1750亿参数语言模型的训练任务中,总训练时间从此前的25天大幅缩短至约10天,效率提升了60%。这意味着客户能够以更快的速度进行模型迭代和创新。
· GPU资源充分利用:客户反馈,新集群的整体GPU利用率(MFU)始终保持在极高水平。我们设计的融合网络架构,成功承载了TB级的模型检查点写入存储的峰值流量,同时并未影响集群的正常运行,证明了该架构的稳定性和高效率。
· 开后前沿探索:凭借新集群强大的算力,客户已经开始着手进行更大规模的多模态模型和科学计算项目的探索,为其在AI领域的持续领先奠定了坚实的基础。
四、总结
本次项目的成功交付,充分体现了我公司在顶级AI算力基础设施领域的深厚技术实力和方案整合能力。正阳不仅仅是硬件的提供商,更是客户业务目标的使能者。通过将最前沿的技术(如H200、400GIB),以精益、高效、贴合客户实际需求的架构进行整合,我们成功地将强大的算力转化为了客户实实在在的生产力与创新力。


